MySQL优化器
目标
给定一个SQL,查找SQL最优(局部最优)的执行路径,使得用户能够更快的得到SQL的执行结果。
指标
CBO方式成本的计算
Total cost = CPU cost + IO cost
CPU cost计算模型
CPU cost = rows/5 + (rows/10 if comparing key)
CPU cost:
- MySQL上层,处理返回记录所花开销
- CPU Cost=records/TIME_FOR_COMPARE=Records/5
- 每5条记录处的时间,作为1 Cost
IO cost计算模型

IO cost以聚集索引叶子节点的数量进行计算
- 全扫描
IO Cost = table stat_clustered_index_size
聚簇索引page总数,一个page作为1 cost - 范围扫描
IO Cost = [(ranges+rows)/total_rows]*全扫描IO Cost
聚簇索引范围扫描与返回记录成比率

若需要回表,则IO cost以预估的记录数量进行计算,开销相当巨大
- 二级索引之索引覆盖扫描
- 索引覆盖扫描,减少返回聚簇索引的IO代价
keys_per_block=(stats_block_size/2)/(key_info[keynr].key_lenth+ref_length+1)
stats_block_size/2 = 索引页半满 - IO Cost:(records+keys_per_block-1)/keys_per_block
- 计算range占用多少个二级索引页面,既为索引覆盖扫描的IO Cost
- 索引覆盖扫描,减少返回聚簇索引的IO代价
- 二级索引之索引非覆盖扫描
- 索引非覆盖扫描,需要回聚簇索引读取完整记录,增加IO代价
- IO Cost = (range+rows)
- range:多少个范围
对于IN查询,就会转换为多个索引范围查询 - row:为范围中一共有多少记录
由于每一条记录都需要返回聚簇索引,因此每一条记录都会产生1 Cost
Cost模型分析
- 聚簇索引扫描代价为索引页面总数量
- 二级索引覆盖扫描代价较小
- 二级索引非覆盖扫描,代价巨大
- Cost模型的计算,需要统计信息的支持
- stat_clustered_index_size
- ranges
- records/rows
- stats_block_size
- key_info[keynr].key_length
- rec_per_key
- ……
MySQL优化总流程
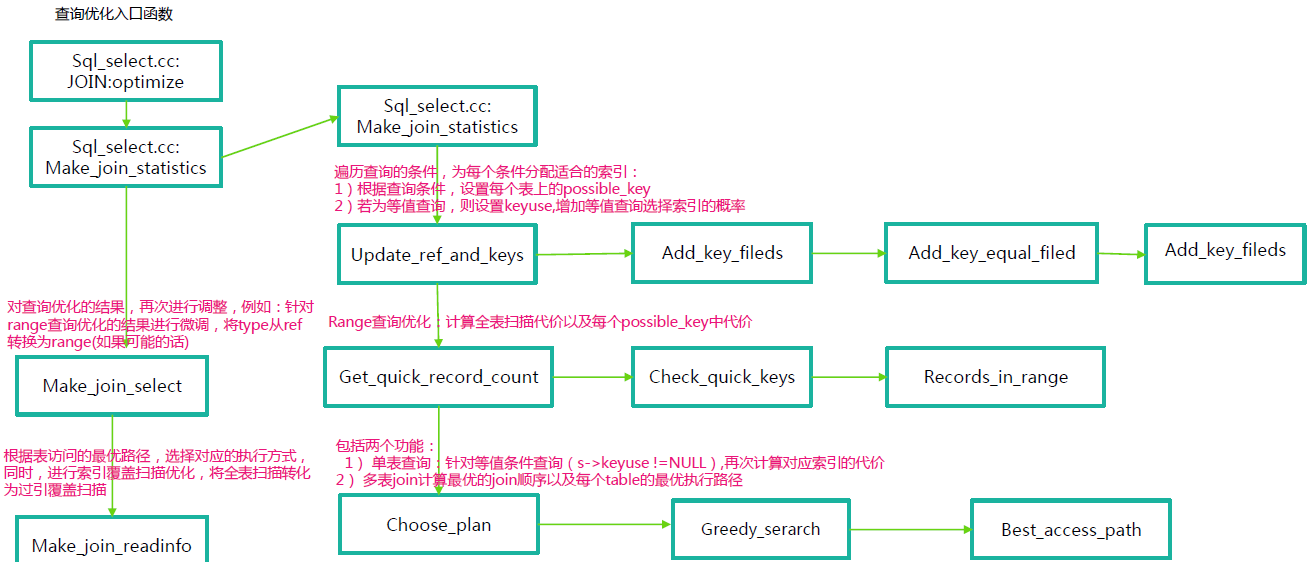
索引元数据的统计
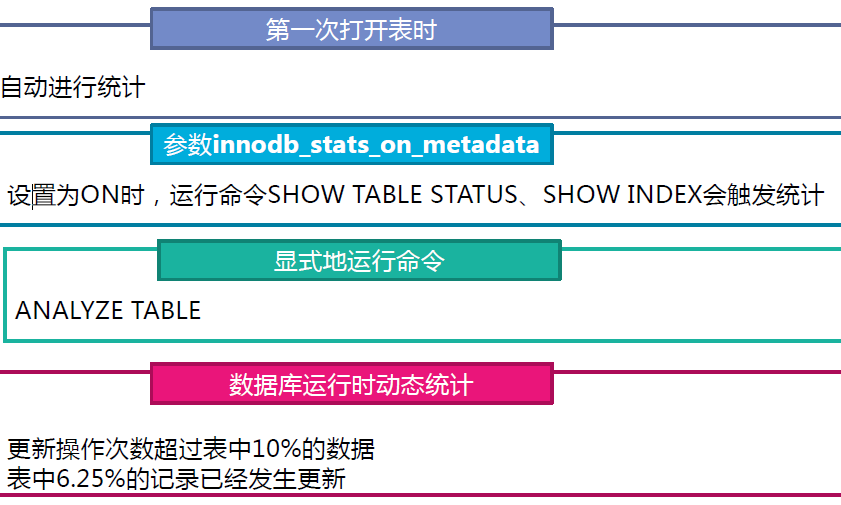
随机抽样统计元数据参数
innodb_stats_sample_pages (5.5版本)
innodb_stats_transient_sample_pages (5.6版本)
MySQL 5.6版本默认持久化索引元数据参数
innodb_stats_persistent
nnodb_stats_persistent_sample_pages
innodb_stats_on_metadata
innodb_stats_auto_recalc
实验
测试环境脚本
drop database lyj; create database lyj; use lyj; create table t1 ( c1 int(11) not null default '0', c2 varchar(128) default null, c3 varchar(64) default null, c4 int(11) default null, primary key (c1), key ind_c2 (c2), key ind_c4 (c4)); insert into t1 values(1,'a','A',10); insert into t1 values(2,'b','B',20); insert into t1 values(3,'b','BB',20); insert into t1 values(4,'b','BBB',30); insert into t1 values(5,'b','BBB',40); insert into t1 values(6,'c','C',50); insert into t1 values(7,'d','D',60); commit; select * from t1; +----+------+------+------+ | c1 | c2 | c3 | c4 | +----+------+------+------+ | 1 | a | A | 10 | | 2 | b | B | 20 | | 3 | b | BB | 20 | | 4 | b | BBB | 30 | | 5 | b | BBB | 40 | | 6 | c | C | 50 | | 7 | d | D | 60 | +----+------+------+------+ |
执行以下SQL为什么不走索引ind_c2?
mysql> explain select * from t1 where c4=20 and c2='b'\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: ref possible_keys: ind_c2,ind_c4,ind_c2_c4 key: ind_c4 key_len: 5 ref: const rows: 2 Extra: Using where set optimizer_trace='enabled=on'; set optimizer_trace_max_mem_size=1000000; set end_markers_in_json=on; select * from t1 where c4=20 and c2='b'; mysql> select * from information_schema.optimizer_trace\G; *************************** 1. row *************************** QUERY: select * from t1 where c4=20 and c2='b' TRACE: { ...... "potential_range_indices": [ # 列出备选索引 { "index": "PRIMARY", "usable": false, # 本行表明主键索引不可用 "cause": "not_applicable" }, { "index": "ind_c2", "usable": true, "key_parts": [ "c2", "c1" ] /* key_parts */ }, { "index": "ind_c4", "usable": true, "key_parts": [ "c4", "c1" ] /* key_parts */ } ] /* potential_range_indices */, "setup_range_conditions": [ ] /* setup_range_conditions */, "group_index_range": { "chosen": false, "cause": "not_group_by_or_distinct" } /* group_index_range */, "analyzing_range_alternatives": { # 开始计算每个索引做范围扫描的花费 "range_scan_alternatives": [ { "index": "ind_c2", "ranges": [ "b <= c2 <= b" ] /* ranges */, "index_dives_for_eq_ranges": true, "rowid_ordered": true, "using_mrr": false, "index_only": false, "rows": 4, # c2=b的结果有4行 "cost": 5.81, "chosen": false, # 这个索引没有被选中,原因是cost "cause": "cost" }, { "index": "ind_c4", "ranges": [ "20 <= c4 <= 20" ] /* ranges */, "index_dives_for_eq_ranges": true, "rowid_ordered": true, "using_mrr": false, "index_only": false, "rows": 2, "cost": 3.41, "chosen": true # 这个索引的代价最小,被选中 } ...... "chosen_range_access_summary": { # 总结:因为cost最小选择了ind_c4 "range_access_plan": { "type": "range_scan", "index": "ind_c4", "rows": 2, "ranges": [ "20 <= c4 <= 20" ] /* ranges */ } /* range_access_plan */, "rows_for_plan": 2, "cost_for_plan": 3.41, "chosen": true } /* chosen_range_access_summary */ ...... |
因为ind_c4范围扫描的cost要小于ind_c2,所以索引不走ind_c2
where条件中字段c2和c4换个位置,索引还是不走ind_c2?为什么?
explain select * from t1 where c2='b' and c4=20\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: ref possible_keys: ind_c2,ind_c4,ind_c2_c4 key: ind_c4 key_len: 5 ref: const rows: 2 Extra: Using where |
因为ind_c4范围扫描的cost要小于ind_c2,所以索引不走ind_c2,跟c2和c4的位置无关。验证方法同上。
如下语句,换个条件c2=’c’,为什么可以走索引ind_c2?
mysql> explain select * from t1 where c2='c' and c4=20\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: ref possible_keys: ind_c2,ind_c4,ind_c2_c4 key: ind_c2 key_len: 387 ref: const rows: 1 Extra: Using index condition; Using where mysql> select * from information_schema.optimizer_trace\G; *************************** 1. row *************************** QUERY: select * from t1 where c2='c' and c4=20 TRACE: { ...... "analyzing_range_alternatives": { "range_scan_alternatives": [ { "index": "ind_c2", "ranges": [ "c <= c2 <= c" ] /* ranges */, "index_dives_for_eq_ranges": true, "rowid_ordered": true, "using_mrr": false, "index_only": false, "rows": 1, # c2=c 的结果集有1行 "cost": 2.21, "chosen": true # 这个索引的代价最小,被选中 }, { "index": "ind_c4", "ranges": [ "20 <= c4 <= 20" ] /* ranges */, "index_dives_for_eq_ranges": true, "rowid_ordered": true, "using_mrr": false, "index_only": false, "rows": 2, "cost": 3.41, "chosen": false, # 这个索引没有被选中,原因是cost "cause": "cost" } ...... |
创建复合索引
ALTER TABLE t1 ADD KEY ind_c2_c4(c2,c4);
|
下面语句为什么不走复合索引ind_c2_c4?explain select * from t1 where c2='b' and c4=20\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ref
possible_keys: ind_c2,ind_c4,ind_c2_c4
key: ind_c4
key_len: 5
ref: const
rows: 2
Extra: Using where
set optimizer_trace='enabled=on';
set optimizer_trace_max_mem_size=1000000;
set end_markers_in_json=on;
select * from t1 where c2='b' and c4=20;
select * from information_schema.optimizer_trace\G;
*************************** 1. row ***************************
QUERY: select * from t1 where c2='b' and c4=20
TRACE: {
......
"potential_range_indices": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "ind_c2",
"usable": true,
"key_parts": [
"c2",
"c1"
] /* key_parts */
},
{
"index": "ind_c4",
"usable": true,
"key_parts": [
"c4",
"c1"
] /* key_parts */
},
{
"index": "ind_c2_c4",
"usable": true,
"key_parts": [
"c2",
"c4",
"c1"
] /* key_parts */
}
] /* potential_range_indices */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "ind_c2",
"ranges": [
"b <= c2 <= b"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 4,
"cost": 5.81,
"chosen": false,
"cause": "cost"
},
{
"index": "ind_c4",
"ranges": [
"20 <= c4 <= 20"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 2,
"cost": 3.41,
"chosen": true
},
{
"index": "ind_c2_c4",
"ranges": [
"b <= c2 <= b AND 20 <= c4 <= 20"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 2,
"cost": 3.41,
"chosen": false,
"cause": "cost"
}
......
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "ind_c4",
"rows": 2,
"ranges": [
"20 <= c4 <= 20"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 2,
"cost_for_plan": 3.41,
"chosen": true
} /* chosen_range_access_summary */
} /* range_analysis */
}
......
索引ind_c4和ind_c2_c4都是非覆盖扫描,而ind_c4和ind_c2_c4的cost是一样的,mysql会选择叶子块数量较少的那个索引,很明显ind_c4叶子块数量较少。
下面语句为什么又可以走复合索引ind_c2_c4?explain select c2,c4 from t1 where c2='b' and c4=20\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ref
possible_keys: ind_c2,ind_c4,ind_c2_c4
key: ind_c2_c4
key_len: 392
ref: const,const
rows: 2
Extra: Using where; Using index
set optimizer_trace='enabled=on';
set optimizer_trace_max_mem_size=1000000;
set end_markers_in_json=on;
select c2,c4 from t1 where c2='b' and c4=20;
select * from information_schema.optimizer_trace\G;
*************************** 1. row ***************************
QUERY: select c2,c4 from t1 where c2='b' and c4=20
TRACE: {
......
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "ind_c2",
"ranges": [
"b <= c2 <= b"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 4,
"cost": 5.81,
"chosen": false,
"cause": "cost"
},
{
"index": "ind_c4",
"ranges": [
"20 <= c4 <= 20"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 2,
"cost": 3.41,
"chosen": false,
"cause": "cost"
},
{
"index": "ind_c2_c4",
"ranges": [
"b <= c2 <= b AND 20 <= c4 <= 20"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": true, # 索引覆盖扫描
"rows": 2,
"cost": 3.41,
"chosen": false,
"cause": "cost"
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"intersecting_indices": [
{
"index": "ind_c2_c4",
"index_scan_cost": 1.0476,
"cumulated_index_scan_cost": 1.0476,
"disk_sweep_cost": 0,
"cumulated_total_cost": 1.0476,
"usable": true,
"matching_rows_now": 2,
"isect_covering_with_this_index": true,
"chosen": true
}
] /* intersecting_indices */,
"clustered_pk": {
"clustered_pk_added_to_intersect": false,
"cause": "no_clustered_pk_index"
} /* clustered_pk */,
"chosen": false,
"cause": "too_few_indexes_to_merge"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`t1`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "ind_c2",
"rows": 4,
"cost": 2.8,
"chosen": true
},
{
"access_type": "ref",
"index": "ind_c4",
"rows": 2,
"cost": 2.4,
"chosen": true
},
{
"access_type": "ref",
"index": "ind_c2_c4",
"rows": 2,
"cost": 1.4476,
"chosen": true
},
{
"access_type": "scan",
"cause": "covering_index_better_than_full_scan",
"chosen": false
}
] /* considered_access_paths */
} /* best_access_path */,
"cost_for_plan": 1.4476,
"rows_for_plan": 2,
"chosen": true
}
......
因为语中ind_c2_c4是索引覆盖扫描,不需要回表,代价较小。
查看索引元数据持久化
select * from mysql.innodb_table_stats where table_name='t1'; +---------------+------------+---------------------+--------+----------------------+--------------------------+ | database_name | table_name | last_update | n_rows | clustered_index_size | sum_of_other_index_sizes | +---------------+------------+---------------------+--------+----------------------+--------------------------+ | lyj | t1 | 2017-10-24 16:39:48 | 7 | 1 | 2 | +---------------+------------+---------------------+--------+----------------------+--------------------------+ select * from mysql.innodb_index_stats where table_name='t1'; +---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+ | database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description | +---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+ | lyj | t1 | PRIMARY | 2017-10-24 15:17:27 | n_diff_pfx01 | 7 | 1 | c1 | | lyj | t1 | PRIMARY | 2017-10-24 15:17:27 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index | | lyj | t1 | PRIMARY | 2017-10-24 15:17:27 | size | 1 | NULL | Number of pages in the index | | lyj | t1 | ind_c2 | 2017-10-24 15:17:27 | n_diff_pfx01 | 4 | 1 | c2 | | lyj | t1 | ind_c2 | 2017-10-24 15:17:27 | n_diff_pfx02 | 7 | 1 | c2,c1 | | lyj | t1 | ind_c2 | 2017-10-24 15:17:27 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index | | lyj | t1 | ind_c2 | 2017-10-24 15:17:27 | size | 1 | NULL | Number of pages in the index | | lyj | t1 | ind_c2_c4 | 2017-10-24 16:39:48 | n_diff_pfx01 | 4 | 1 | c2 | | lyj | t1 | ind_c2_c4 | 2017-10-24 16:39:48 | n_diff_pfx02 | 6 | 1 | c2,c4 | | lyj | t1 | ind_c2_c4 | 2017-10-24 16:39:48 | n_diff_pfx03 | 7 | 1 | c2,c4,c1 | | lyj | t1 | ind_c2_c4 | 2017-10-24 16:39:48 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index | | lyj | t1 | ind_c2_c4 | 2017-10-24 16:39:48 | size | 1 | NULL | Number of pages in the index | | lyj | t1 | ind_c4 | 2017-10-24 15:17:27 | n_diff_pfx01 | 6 | 1 | c4 | | lyj | t1 | ind_c4 | 2017-10-24 15:17:27 | n_diff_pfx02 | 7 | 1 | c4,c1 | | lyj | t1 | ind_c4 | 2017-10-24 15:17:27 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index | | lyj | t1 | ind_c4 | 2017-10-24 15:17:27 | size | 1 | NULL | Number of pages in the index | +---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+ |